- 软件


/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/
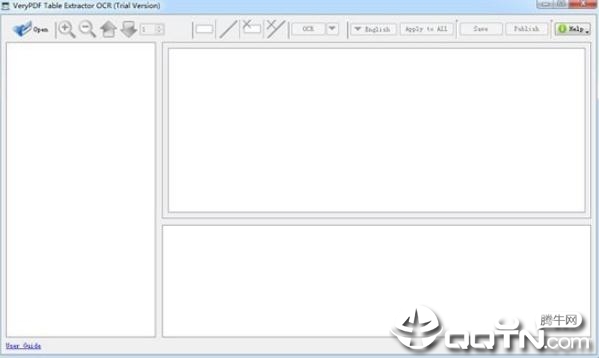
VeryPDF Table Extractor OCR是一款可以支持从各种PDF文件和图像中提取文字的识别软件。可以支持在Windows和Mac OS X系统中运行,支持多种语言,多种文件格式使用,提高文字工作者的工作效率,需要的用户赶快来下载这款工具吧!
Mac OS X和Windows用户的两个版本。
VeryPDF Table Extractor OCR官方版支持各种输入输出格式。
支持在线发布。
支持多种语言。
输入文件格式:PDF、BMP、JPG、JPEG、JPE和GIF。
输出文件格式:csv、xls、html、pptx、docx、xlsx、rtf和txt。
将当前页的规则应用于所有其余页。
允许预览原始表和结果表并进行比较。
单击主界面上的文本时,突出显示相应的原始文本。
支持放大和缩小功能。
通过更改阈值,将输入文件的颜色更改为黑白。
清除充满点和斑点的输入文件。
当倾斜角度小于15度时,自动消除输入文件。
将输入文件旋转不同的角度。
提高输入文件的质量。
拆下桌子框架。
删除单元格背景。
选择要OCR的输入文件每页的任何区域。

从扫描的或普通的PDF文档中提取表
VeryPDF Table Extractor OCR官方版支持使用光学字符识别技术从普通的PDF或扫描的PDF文档中提取表格,效率和质量都很高。在提取的表中,还可以根据需要添加或删除垂直线。
去纸和去纸输入PDF文档
允许在15度范围内倾斜输入的PDF文档。它还支持使用干净的工具去检查充满点和斑点的PDF文档,最后创建一个新的干净文档。
在Windows和Mac OS X系统中运行
专为不同用户设计的Windows和Mac OS X系统。这两个版本的操作方法和界面是相同的。如果你能掌握一个版本,你就可以自由使用另一个版本。
利用计算机自动识别字符的技术,是模式识别应用的一个重要领域。人们在生产和生活中,要处理大量的文字、报表和文本。为了减轻人们的劳动,提高处理效率
50年代开始探讨一般文字识别方法,并研制出光学字符识别器。60年代出现了采用磁性墨水和特殊字体的实用机器。
60年代后期,出现了多种字体和手写体文字识别机,其识别精度和机器性能都基本上能满足要求。如用于信函分拣的手写体数字识别机和印刷体英文数字识别机。
70年代主要研究文字识别的基本理论和研制高性能的文字识别机,并着重于汉字识别的研究。

 CorelCAD 2021(附破解补丁)
CorelCAD 2021(附破解补丁) Skeez Tutorial(动画列表视图工具)
Skeez Tutorial(动画列表视图工具) VectorWorks InteriorCAD2021
VectorWorks InteriorCAD2021 HandyCam(AE控制摄像机动画)
HandyCam(AE控制摄像机动画) XTrackCAD(模型RR轨道规划器)
XTrackCAD(模型RR轨道规划器) Block Swap(AE随机生成像素块视觉特效)
Block Swap(AE随机生成像素块视觉特效) MAX管家素材管理系统
MAX管家素材管理系统 abelssoft Screenphoto
abelssoft Screenphoto Particle Projection
Particle Projection 逸鑫网店卖家图片处理软件
逸鑫网店卖家图片处理软件





 7-zip下载v18.03 简体中文美化版压缩解压
7-zip下载v18.03 简体中文美化版压缩解压 数独计算器v1.2 免安装版教育学习
数独计算器v1.2 免安装版教育学习 Boilsoft FLV Converterv1.6 绿色版格式转换
Boilsoft FLV Converterv1.6 绿色版格式转换 微简vipage(代码自动生成器)v4.2 官方版编程开发
微简vipage(代码自动生成器)v4.2 官方版编程开发 磁盘加密软件CnCrypt下载v1.23 官方版加密解密
磁盘加密软件CnCrypt下载v1.23 官方版加密解密 2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全
2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全 新科图库v1.1 正式版图像管理
新科图库v1.1 正式版图像管理 吾爱倒计时v1.0.1 中文版开关定时
吾爱倒计时v1.0.1 中文版开关定时 局域网共享精灵v10.6 官方绿色版网络共享
局域网共享精灵v10.6 官方绿色版网络共享 粤公网安备 42011102000245号
粤公网安备 42011102000245号