- 软件


/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/
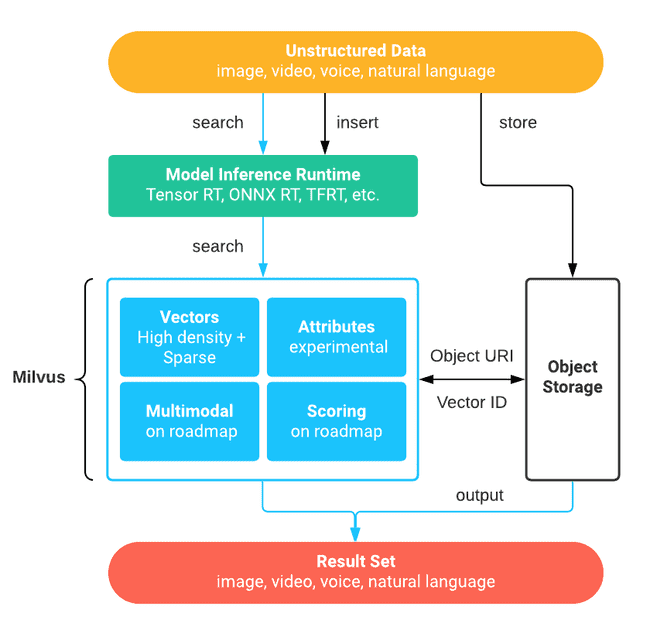
Milvus是一款开源的向量数据库,使用方便、实用可靠、易于扩展、稳定高效和搜索迅速,提供了一整套简单直观的 API,让你可以针对不同场景选择不同的索引类型,常用于媒体、文本搜索以及新药搜索、基因筛选等领域,欢迎下载使用!

全面的相似度指标
Milvus 支持各种常用的相似度计算指标,包括欧氏距离、内积、汉明距离和杰卡德距离等。您可以根据应用需求来选择最有效的向量相似度计算方式。
业界领先的性能
Milvus 基于高度优化的 Approximate Nearest Neighbor Search (ANNS) 索引库构建,包括 faiss、 annoy、和 hnswlib 等。您可以针对不同使用场景选择不同的索引类型。
动态数据管理
您可以随时对数据进行插入、删除、搜索、更新等操作而无需受到静态数据带来的困扰。
近实时搜索
在插入或更新数据之后,您可以几乎立刻对插入或更新过的数据进行搜索。Milvus 负责保证搜索结果的准确率和数据一致性。
高成本效益
Milvus 充分利用现代处理器的并行计算能力,可以在单台通用服务器上完成对十亿级数据的毫秒级搜索。
支持多种数据类型和高级搜索
Milvus 的数据记录中的字段支持多种数据类型。您还可以对一个或多个字段使用高级搜索,例如过滤、排序和聚合。
高扩展性和可靠性
您可以在分布式环境中部署 Milvus。如果要对集群扩容或者增加可靠性,您只需增加节点。
云原生
您可以轻松在公有云、私有云、或混合云上运行 Milvus。
简单易用
Milvus 提供了易用的 Python、Java、Go 和 C++ SDK,另外还提供了 RESTful API。
异构计算
优化了基于 GPU 搜索向量和建立索引的性能。
可以在单台通用服务器上完成对 TB 级数据的毫秒级搜索。
动态数据管理。
支持主流索引库、距离计算方式和监控工具
集成了 Faiss、NMSLIB、Annoy 等向量索引库。
支持基于量化的索引、基于图的索引和基于树的索引。
相似度计算方式包括欧氏距离 (L2)、内积 (IP)、汉明距离、杰卡德距离等。
Prometheus 作为监控和性能指标存储方案,Grafana 作为可视化组件进行数据展示。
近实时搜索
插入 Milvus 的数据默认在 1 秒后即可被搜索到。
标量字段过滤 (即将上线)
支持向量和标量数据。
可以对标量数据进行过滤,增强搜索的灵活性。
新功能
#4564支持在get_entity_by_id()方法调用中指定分区。
#4806 支持在delete_entity_by_id()方法的调用中指定分区。
#4905 增加了release_collection()方法,从缓存中卸载一个特定的集合。
改进之处
#4756 提高了get_entity_by_id()方法调用的性能。
#4856 将hnswlib升级到v0.5.0。
#4958提高了IVF索引训练的性能。
修复的问题
#4778 在Mishards中访问向量索引失败。
#4797 合并具有不同topK参数的搜索请求后,系统返回错误结果。
#4838 服务器不会立即响应空集合上的索引构建请求。
#4858 对于支持GPU的Milvus,系统在有大topK(> 2048)的搜索请求时崩溃。
#4862 一个只读的节点在启动过程中会合并片段。
#4894 布隆过滤器的容量不等于它所属段的行数。
#4908 在放弃一个集合后,GPU缓存没有被清理。
#4933 系统需要很长时间才能为一个小段建立索引。
#4952 未能将时区设置为 "UTC + 5:30"。
#5008 在连续、并发的删除、插入和搜索操作中,系统随机崩溃。
#5010 对于支持GPU的Milvus,如果nbits≠8,在IVF_PQ上查询失败。
#5050 get_collection_stats()对仍在建立索引过程中的段返回错误的索引类型。
#5063 当一个空段被刷新时,系统会崩溃。
#5078 对于支持GPU的Milvus,在2048、4096或8192维度的向量上创建IVF索引时系统崩溃。

 Scarab Darkroom(数码暗房)
Scarab Darkroom(数码暗房) Video to Picture(视频转图像)
Video to Picture(视频转图像) Acon Digital Equalize(音乐均衡器)
Acon Digital Equalize(音乐均衡器) Kabuu Audio Converter(音频转换器)
Kabuu Audio Converter(音频转换器) CAD云服务(自动转T3格式)
CAD云服务(自动转T3格式) TLP音乐工具箱
TLP音乐工具箱 脉冲语音合成器
脉冲语音合成器 V-Can(视频拼接软件)
V-Can(视频拼接软件) 爱转换PDF转换器
爱转换PDF转换器 Easy M4V Converter(M4V转换器)
Easy M4V Converter(M4V转换器)











 核桃编程电脑版编程开发 / 272.4M
核桃编程电脑版编程开发 / 272.4M Apifox(接口调试工具)编程开发 / 129.5M
Apifox(接口调试工具)编程开发 / 129.5M scratch编程软件电脑版编程开发 / 161.3M
scratch编程软件电脑版编程开发 / 161.3M ApiPost接口调试与文档生成工具编程开发 / 90.3M
ApiPost接口调试与文档生成工具编程开发 / 90.3M 编程猫公测版编程开发 / 54.6M
编程猫公测版编程开发 / 54.6M tortoisegit中文语言包下载编程开发 / 13.1M
tortoisegit中文语言包下载编程开发 / 13.1M SVN客户端TortoiseSVN编程开发 / 20.2M
SVN客户端TortoiseSVN编程开发 / 20.2M 快手aardio下载编程开发 / 9.3M
快手aardio下载编程开发 / 9.3M Microsoft Visual Studio 2022编程开发 / 1.3M
Microsoft Visual Studio 2022编程开发 / 1.3M 7-zip下载v18.03 简体中文美化版压缩解压
7-zip下载v18.03 简体中文美化版压缩解压 数独计算器v1.2 免安装版教育学习
数独计算器v1.2 免安装版教育学习 Boilsoft FLV Converterv1.6 绿色版格式转换
Boilsoft FLV Converterv1.6 绿色版格式转换 微简vipage(代码自动生成器)v4.2 官方版编程开发
微简vipage(代码自动生成器)v4.2 官方版编程开发 磁盘加密软件CnCrypt下载v1.23 官方版加密解密
磁盘加密软件CnCrypt下载v1.23 官方版加密解密 2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全
2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全 新科图库v1.1 正式版图像管理
新科图库v1.1 正式版图像管理 吾爱倒计时v1.0.1 中文版开关定时
吾爱倒计时v1.0.1 中文版开关定时 局域网共享精灵v10.6 官方绿色版网络共享
局域网共享精灵v10.6 官方绿色版网络共享 粤公网安备 42011102000245号
粤公网安备 42011102000245号