- 软件


/中文/

/中文/

/中文/
/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/
软件Tags: CrawlWorm Picture下载工具图片爬取
CrawlWorm Picture是一款网站图片爬取工具,能够帮助用户下载网页中的全部图像内容,只需要输入链接即可,下载速度快,适合各种自媒体搬运用户,有需要的用户不要错过了,赶快来下载吧!
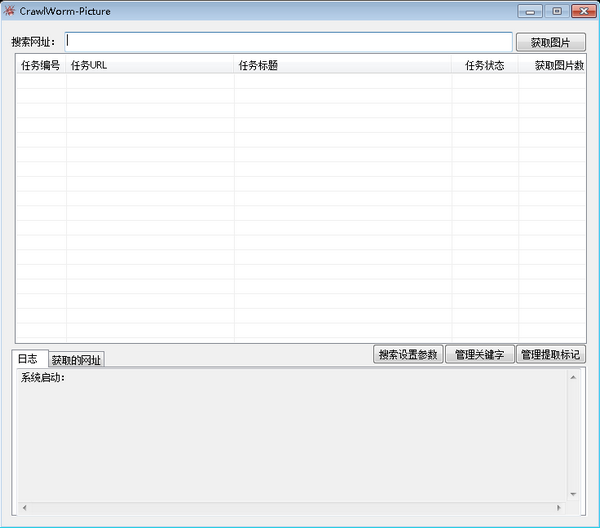
本软件属于网络类应用软件,在Windows平台使用的网络图片爬取工具,主要功能为根据提供的网站地址,分析网页源码获取网站的图片资源,能够实现简单分类并存储到数据库和硬盘中。
(1)本技术需配合SQL Server数据库使用
(2)获取图片
在获取图片时,需要用户自己输入要抓取的根网址,这里的根网址需要保证其真实存在,如果不存在则会提示网页源代码获取失败,从而导致任务启动失败。
(3)搜索参数设置
在搜索参数设置的时候,需要慎重考虑其各个参数之间的制约关系,有以下几种情况需要说明。
如果搜索深度设置过大,那么就需要将抓取数据容量设置的大一些,否则任务会因为抓取容量不足而被迫停止抓取工作。
如果能够保证自己的网络连接正常,则选择不使用代理服务器。因为使用代理服务器,在任务执行过程中,如果代理服务器失效或者停止活动,则需要重新选择代理服务器,这中间会耗费大量时间来更换代理服务器。
在选择开始执行时间时,不易将执行时间设置的过长,因为设置的过长会使任务长期处于等待状态,建议只有在任务较少的情况下这样设置。
(4)关键字管理
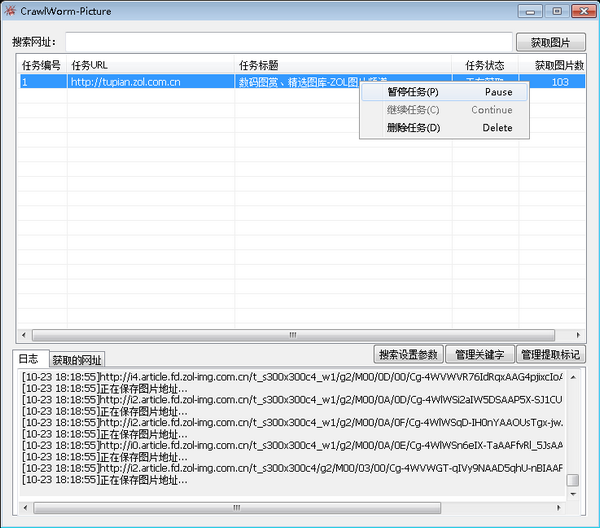
在关键字管理中,需要注意的是在添加主关键字的时候,要同时添加一个与主关键字名字相同的子关键字,因为在图片进行分类的时候,首先比对的是子关键字,只有子关键字匹配之后才能确定其分类归属。
另外需要注意的是,删除主关键字时会将与其相关的所有子关键字一同删除。
(5)多任务
鉴于对任务耗费资源的考虑,同时执行的任务个数设定为5个,超过5个的任务只能处于等待状态,只有5个被执行任务中有结束的,处于等待的任务才能被执行。
1.优化了用户使用界面
2.修复了某些已知bug

 小米云服务客户端
小米云服务客户端 geeLevel秒点
geeLevel秒点 小K极速浏览器
小K极速浏览器 极连快传电脑版
极连快传电脑版 迅雷11正式版客户端
迅雷11正式版客户端 firefox火狐浏览器32位PC版下载
firefox火狐浏览器32位PC版下载 中国移动云盘pc版
中国移动云盘pc版 ToDesk(远程协助软件)
ToDesk(远程协助软件) AnyViewer(傲梅远程桌面控制工具)
AnyViewer(傲梅远程桌面控制工具) 爱思远控pc版
爱思远控pc版











 漫画控下载工具 / 3.0M
漫画控下载工具 / 3.0M BIGEMAP地图下载器Google Earth版下载工具 / 32.6M
BIGEMAP地图下载器Google Earth版下载工具 / 32.6M
 谷谷GIS地图下载器下载工具 / 20.3M
谷谷GIS地图下载器下载工具 / 20.3M 吾爱迅雷下载下载工具 / 3.6M
吾爱迅雷下载下载工具 / 3.6M DownZemAll下载工具 / 27.2M
DownZemAll下载工具 / 27.2M 文献党下载器下载工具 / 5.1M
文献党下载器下载工具 / 5.1M 巴士云网盘下载器下载工具 / 8.1M
巴士云网盘下载器下载工具 / 8.1M MusicTools付费无损音乐免费下载神器下载工具 / 5.1M
MusicTools付费无损音乐免费下载神器下载工具 / 5.1M 7-zip下载v18.03 简体中文美化版压缩解压
7-zip下载v18.03 简体中文美化版压缩解压 数独计算器v1.2 免安装版教育学习
数独计算器v1.2 免安装版教育学习 Boilsoft FLV Converterv1.6 绿色版格式转换
Boilsoft FLV Converterv1.6 绿色版格式转换 微简vipage(代码自动生成器)v4.2 官方版编程开发
微简vipage(代码自动生成器)v4.2 官方版编程开发 磁盘加密软件CnCrypt下载v1.23 官方版加密解密
磁盘加密软件CnCrypt下载v1.23 官方版加密解密 2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全
2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全 新科图库v1.1 正式版图像管理
新科图库v1.1 正式版图像管理 吾爱倒计时v1.0.1 中文版开关定时
吾爱倒计时v1.0.1 中文版开关定时 局域网共享精灵v10.6 官方绿色版网络共享
局域网共享精灵v10.6 官方绿色版网络共享 粤公网安备 42011102000245号
粤公网安备 42011102000245号