- 软件


/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/

/中文/
软件Tags: 水淼万能文章采集器
水淼万能文章采集器这个软件官方报价400元,有网友分享了破解版本,下边在这里分享给需要的用户使用!
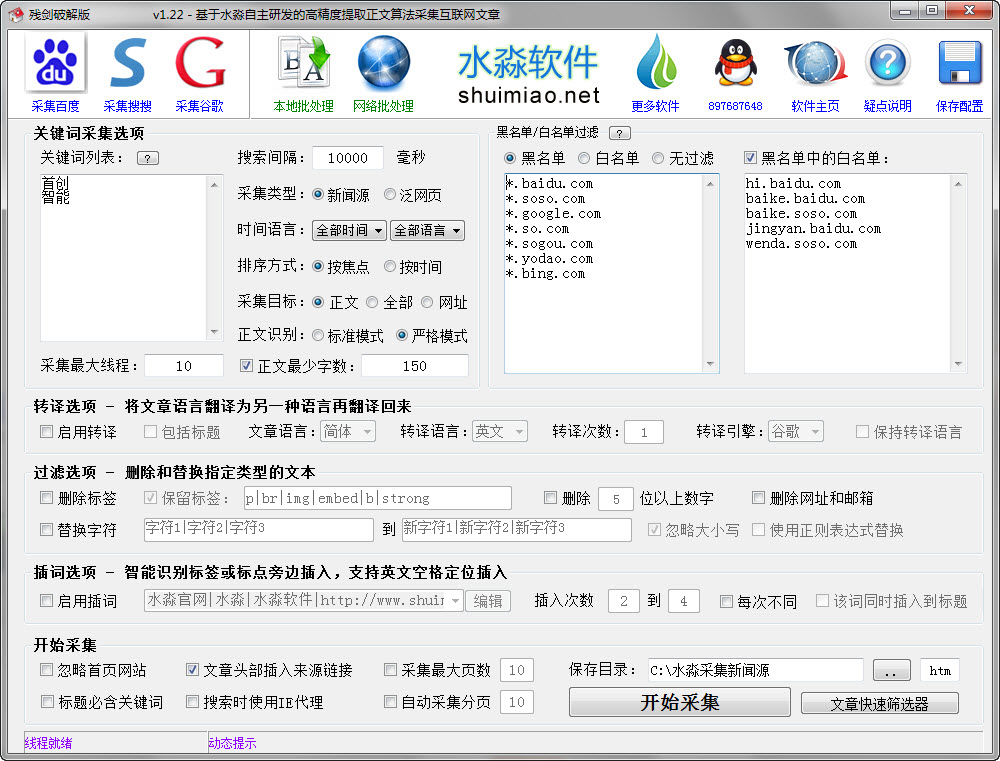
水淼软件出品的一款基于高精度正文识别算法的互联网文章采集器。支持按关键词采集百度等搜索引擎的新闻源(news.baidu.com)和泛网页(www.baidu.com),支持采集指定网站栏目下的全部文章。 更多介绍..
水淼软件独家首创智能的万能算法,可以精确提取网页里的正文部分保存为文章。
支持去标签、链接、邮箱等格式化处理。还有插入关键词功能,可以识别标签或标点旁边插入,并且能识别英文空格间距插入。
更有文章转译功能,也就是可以将文章从一种语言如中文转到另一种语言如英文或日文,再从英文或日文转回中文,这样就是一个转译周期,可以设定转译周期循环多次(转译次数)。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价往往达到上万甚至更多,而水淼的这款软件也是一款信息采集系统,功能跟市面上昂贵售价的软件有相通之处,但价格只有区区几百元,性价比如何试试就知。
什么是高精度正文识别算法
此算法由水淼自主研发,可以在一个网页里提取出正文部分,通常精度可以达到95%,如果再进一步设置最少字数,采集的文章的精度(正确性)可以达到99%。同时文章标题也实现99%的提取精度。当然,一些网页排版格式比较混乱、不规则时,该精度可能有所下降。
正文提取模式
正文提取算法有3种模式,标准、严格、精确标签。大多数情况,标准和严格模式是相同的提取结果。下面说的是特殊情况:
标准模式:即一般性提取,大多数时候能够精确提取正文,但一些特殊页面会导致提取到一些不需要内容(但本模式能够较好识别类似百度经验的文章页面)
严格模式:顾名思义,比标准模式严格一点,可以很大程度避免不相关内容提取为正文,但对于特殊分段页面如百度经验的页面(不是一般<p></p><br>段落,而是有格式的多个独立div段),一般只能提取到某一段,而标准模式则可以提取全部段。
精确标签:当标准和严格模式不管用时,可以精确指定目标正文的标签头。本模式只适合网络批处理。
所以可以根据实际情况来切换模式。可以使用本地批处理的读网页正文功能来测试指定网页适合哪种模式提取。
采集时的处理选项
采集时可以同时进行转译、过滤、查词等处理。对于已采集好的文章可以使用《本地批处理》处理。
其中的转译功能,就是将中文翻译成英文再翻译回中文,也就产生了伪原创效果。支持原格式转译,也就是不改变文章原有标签结构、排版格式。
采集目标为网址
可以在网址模板里插入 #网址#、#标题#来组合引用
分页采集和相对路径转为绝对路径
打勾“自动采集分页”就能将分页文章采集合并,编辑框设置值为采集分页的最大数量。建议设置一个有限值如10页,避免一些分页过多的采集耗费时间长,合并后的文章体积大。如果需要采集全部分页,可以设置为0。
而文章里的所有相对路径都将自动转为绝对路径,如此可确保图片等正常显示。
多线程
支持多线程高速采集网页。可以根据网速而定,电信2m可以5个线程,电信4m可以10个线程,更多以此类推,但需适当设置,设置太多将可能严重影响采集效率甚至影响系统效率。如果采集时有其他占用流量的软件在运行比如在线视频播放,可以适当降低线程数。
文章标题和文章内容重复的处理
程序可以智能判断并过滤重复文章
当采集到的文章标题(文件名)与本地已经保存的文章标题相同时,水淼将首先判断两篇文章的相似度,当相似度大于 60% 时,水淼判断为相同文章,这时再比较两篇文章的文字多寡,自动使用文字多的文章覆盖写出到相同文件名处。这样的生成情况是不累加到生成数量的。
当相似度低于 60% 时,水淼判断为不同文章,将自动重命名标题(取3到5个随机字母接在标题尾)保存到文件。
文章快速筛选器
虽然水淼研究了一个准确率极高的正文提取算法,但难免还是有极少数提取错误,这些错误主要是:目标网页的主体是在线视频,或主体内容过于简短而无法形成正文的特征。因此可以通过设置提取最终结果的字数多少来提高准确率(在“正文最少字数”参数,这个字数是程序将正文去标签、去行、去空格之后的纯文字字数)。
而文章快速筛选器就是为了快速查看采集好的文章,方便判断删除提取正文错误的文章。同时也方便基于网络信息采集目的而需要进行的炼选过程。
生成篇数不固定的问题
百度、搜搜默认每页100条结果,谷歌默认每页10条结果。
一些网站访问速度超时(尤其是谷歌收录的不少都是一些被墙的网站),或设置了正文最少字数,或程序忽略已在本地有同名的相似内容文章,或黑名单白名单的过滤等,都会造成实际生成篇数低于一页搜索最大结果数。
总体来说,百度采集的质量最好,生成篇数贴近搜索结果数。
文字教程:采集指定网站的文章
首先说明一点(以百度举例),新闻源的主页是 news.baidu.com,泛网页的主页是 www.baidu.com,在这个主页里可以输入关键词搜索文章,而程序里给出关键词列表就是由程序来批量搜索网页,并抓取回搜索结果,然后提取结果里的网址,再对这个网址采集目标网页的正文和标题。
泛网页的关键词可以直接使用 site、inurl 等搜索引擎支持的语法,想要采集指定网站就必须选中泛网页单选框。
想要采集百度经验,直接输入关键词 site:jingyan.baidu.com ,即可自动采集百度经验上的文章
(在采集百度经验时,如果启用黑名单,需去掉 *.baidu.com 项,或在黑名单中的白名单里添加 jingyan.baidu.com 项;也可以直接选无过滤)。
另外,指定采集某网站时,请将线程数量设置为1或2个,否则过多线程同时对一个网站进行访问,第一可能会造成该网站的反应效率问题,反而采集更慢,同时也影响别人对该网站的访问体验,第二是如果该网站有监测功能发现你多个线程在对着他访问,可能会直接屏蔽掉你的访问。

 上海证券卓越版金融终端版
上海证券卓越版金融终端版 Z-Factory实在智能RPA
Z-Factory实在智能RPA 牛奶配送管理系统专业版
牛奶配送管理系统专业版 exwinner报价软件
exwinner报价软件 增值税发票开票软件(税务UKey版)
增值税发票开票软件(税务UKey版) 柠檬云财务软件
柠檬云财务软件 同花顺远航版
同花顺远航版 呱呱财经视频电脑版
呱呱财经视频电脑版 饿了么商家版电脑端
饿了么商家版电脑端 晴天彩票分析选号软件
晴天彩票分析选号软件






 非常好印(PrintMagic)出版印刷 / 166.3M
非常好印(PrintMagic)出版印刷 / 166.3M 精诚印刷报价软件出版印刷 / 12.6M
精诚印刷报价软件出版印刷 / 12.6M i印通自助打印平台出版印刷 / 120.7M
i印通自助打印平台出版印刷 / 120.7M 打单助手软件出版印刷 / 94.7M
打单助手软件出版印刷 / 94.7M Affinity Publisher(附激活序列号)出版印刷 / 299.2M
Affinity Publisher(附激活序列号)出版印刷 / 299.2M MatterControl(开源3D打印机控制器)出版印刷 / 15.7M
MatterControl(开源3D打印机控制器)出版印刷 / 15.7M QuarkXPress2020(附破解补丁)出版印刷 / 945M
QuarkXPress2020(附破解补丁)出版印刷 / 945M QuarkCopyDesk(出版图文编辑)出版印刷 / 648KB
QuarkCopyDesk(出版图文编辑)出版印刷 / 648KB 7-zip下载v18.03 简体中文美化版压缩解压
7-zip下载v18.03 简体中文美化版压缩解压 数独计算器v1.2 免安装版教育学习
数独计算器v1.2 免安装版教育学习 Boilsoft FLV Converterv1.6 绿色版格式转换
Boilsoft FLV Converterv1.6 绿色版格式转换 微简vipage(代码自动生成器)v4.2 官方版编程开发
微简vipage(代码自动生成器)v4.2 官方版编程开发 磁盘加密软件CnCrypt下载v1.23 官方版加密解密
磁盘加密软件CnCrypt下载v1.23 官方版加密解密 2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全
2017异鬼Ⅱ病毒免疫工具腾讯电脑管家查杀v1.0 最新版系统安全 新科图库v1.1 正式版图像管理
新科图库v1.1 正式版图像管理 吾爱倒计时v1.0.1 中文版开关定时
吾爱倒计时v1.0.1 中文版开关定时 局域网共享精灵v10.6 官方绿色版网络共享
局域网共享精灵v10.6 官方绿色版网络共享 粤公网安备 42011102000245号
粤公网安备 42011102000245号